개요
해당 글에서는 Muesli의 loss에 대해 추가적인 설명을 작성합니다.
먼저 뮤즐리는 뮤제로의 후속 연구로 많은 것을 뮤제로와 공유하는데, loss가 서로 다릅니다. 뮤제로는 self-play시에 action-selection을 위해서 수십~수백번의 MCTS실행을 통해서 search policy를 얻어내고 이에 따라 액션을 취합니다. (뮤즐리는 많은 알고리즘들과 유사하게 그냥 policy를 따라 액션을 선택합니다. 이 때문에 Self-play시에 훨씬 빠릅니다.) 그리고 뮤제로는 학습 시 self-play시에 얻었던 search policy를 unroll된 네트워크가 따라가게끔 둘의 차이를 cross entropy loss로 계산하는 loss를 사용합니다.
이러한 방법이 알파고 제로 때부터 뮤제로까지 효과적으로 쓰여왔는데, 한편으로는 이러한 방식이 다른 policy optimization식들과는 꽤나 다른 모습인 것을 많이들 의아해 했을 것 같습니다. 이러한 물음에서 시작된 것인지, "Monte-Carlo tree search as regularized policy optimization" 라는 논문에서 위에서 설명했던 MCTS를 사용해서 search policy를 찾고 loss를 구성하는 방법이 regularized policy optimization의 objective를 approximate하는 것으로 볼 수 있다는 설명을 내놓았습니다.
뮤즐리는 이러한 아이디어에 기반해 기존 뮤제로의 성능을 따라잡을 수 있는 regularized objective를 제시하였고, 이는 다음과 같습니다.
L_pg+cmpo

레귤라이저 옆의 람다는 하이퍼파라미터입니다. 레귤라이저에 들어가는 pi_cmpo는 다음과 같습니다.
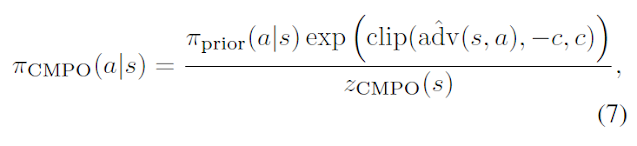
pi_prior는 뮤즐리에서 업데이트되는 네트워크의 파라미터들을 exponential moving average로 저장하는 target network로부터 인퍼런스 되는 policy입니다. 그리고 advantage는 target network의 model(reward model, value model)들로부터 계산합니다. z_cmpo는 모든 action들에 대해서 pi_cmpo 분포를 구성할 때 valid 한 probability distribution임을 보장해주기 위해서 나눠주는 값(분자 계산값 모두 더한값)입니다.
(Loss계산에서 사용되는 모든 advantage들은 normalized되어 사용이 되는데 이는 reward scale에 robust하기 위해 중요한 부분입니다. 이는 설명글에 설명되어 있습니다.)
위의 식을 직접 사용하는 것이 성능상 가장 좋지만 stochastic하게 식을 sample하는 방법도 소개가 됩니다. action space가 큰 경우에 모든 경우에 대해 전부 계산하지 않고 일부에 대해서만 계산하기 위함입니다.

Figure 6(b), KL식 직접 구하는 것과 sampling하는 것과 차이
첫번째 항(9번 식)은 아래의 식으로 샘플됩니다.

두번째 항(7번 식)은 아래의 식으로 샘플됩니다.
 7번 식의 레귤라이저처럼 exact한 분포에 대해 KL을 취하는 대신 선택된 action들(이는 target network로부터 인퍼런스된 pi_prior에 따라 샘플됨)에 대해 각각 거리를 계산할 수 있는 구조로, 여기서의 z_cmpo는 아래의 식이 사용됩니다. z_init은 1이 사용됩니다.
7번 식의 레귤라이저처럼 exact한 분포에 대해 KL을 취하는 대신 선택된 action들(이는 target network로부터 인퍼런스된 pi_prior에 따라 샘플됨)에 대해 각각 거리를 계산할 수 있는 구조로, 여기서의 z_cmpo는 아래의 식이 사용됩니다. z_init은 1이 사용됩니다.

계산된 L_pg_cmpo는 첫번째 policy에 대한 loss로 사용이 됩니다.

L_m
그리고 미래 시점에 인퍼런스된 policy들에 대해서 model loss인 L_m이 사용되는데, 이는 input을 hidden state로 인코딩하는 인코더 역할을 하고 있는 representation network, dynamics network가 hidden state들의 표현을 학습하는데 도움이 되어 학습을 안정적으로 만들어 줍니다. 해당 식에 들어가는 pi_cmpo는 위의 그림에 그려둔 것과 같이 target network를 가지고 각 시점의 observation들로부터 one-step lookahead를 하여 계산합니다.

Figure 7(a), L_m 사용 성능 비교 (5-step, 1-step, 없는경우)

L_r, L_v
그리고 reward model들로 들어가는 L_r 및 value model들로 들어가는 L_v는 해당 시점에서 관찰된 reward와 value 값들을 학습합니다. 해당 값들은 스칼라 값 그대로 학습되는 것이 아니라 categorical reparametrization 기법을 통해서 학습이 됩니다. 이는 (설명글)에서 설명하였습니다.
이렇게 Regularized objective인 L_pg+cmpo, model loss인 L_m, value model과 reward model에 대한 loss L_v, L_r이 모두 합쳐져서 L_total = L_pg_cmpo + L_v/6/4 + L_r/5/1 + L_m의 형태로 들어가게 되고, 한번에 optimize됩니다. (각각 unroll된만큼 나눠지고, L_v의 경우 policy와 네트워크를 공유해서인지 loss를 더 낮춰주는 것이 안정적입니다.)







댓글
댓글 쓰기