개요
REINFORCE 알고리즘을 PyTorch 코드로 구현해보았으며 Colab에서 코드 실행 및 결과 확인이 가능합니다.
설명
REINFORCE 알고리즘은 기본적으로 policy를 따라 움직여 얻어낸 trajectory를 바탕으로 policy의 성능을 나타내는 objective function을 최대화하는 방향으로 직접 policy에 gradient를 먹이는 구조입니다.

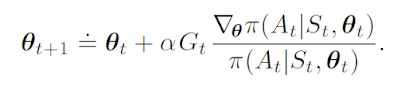

def update_weights(self):
self.optimizer.zero_grad()
G_t = 0
for gradient_policy_a_s, r in self.trajectory[::-1]: #cumulative future rewards들의 합 계산을 위해 [::-1]
G_t = 0.99 * G_t + r
loss = -1 * G_t * gradient_policy_a_s # -1 for gradient ascent
loss.backward()
self.optimizer.step()
self.trajectory.clear()
return
policy를 사용하여 self-play해서 얻어낸 trajectory를 거꾸로 순회하면서 각 time step에 필요한 G_t를 계산해가면서 loss를 구성하고 policy network의 weights들을 업데이트하는 구조입니다.
아래는 매 에피소드마다 CartPole 게임을 self_play하면서 결과로 얻어낸 게임 점수를 나타낸 그래프입니다. 학습이 진행될수록 성능이 올라가는 경향을 보입니다.


Full Code
import gym
import torch
import torch.nn as nn
from torch.distributions import Categorical
import matplotlib.pyplot as plt
!pip install gym[classic_control]
#pip install gym[box2d] #for lunarlander
!apt update
!apt install xvfb
!pip install pyvirtualdisplay
!pip install gym-notebook-wrapper
import gnwrapper
!nvidia-smi
print(torch.cuda.is_available())
class Agent(nn.Module):
def __init__(self, input_dim, output_dim, width):
super().__init__()
self.model = PolicyNetwork(input_dim, output_dim, width)
self.model.to(device)
self.model.train()
self.optimizer = torch.optim.Adam(self.model.parameters(), lr=0.0003)
self.trajectory = []
self.env = gym.make("CartPole-v1")
def forward(self, x):
x = self.model(x)
return x
def self_play(self, max_timestep=1000000):
game_score = 0
state = self.env.reset() # env 시작
for _ in range(max_timestep):
output = self.forward(torch.from_numpy(state).float().to(device)) # inference
prob_distribution = Categorical(output) # 확률분포 표현
action = prob_distribution.sample() # 확률분포로부터 action 선택
state, r, done, _ = self.env.step(action.item()) # env 진행
self.trajectory.append((prob_distribution.log_prob(action), r)) # a,r 저장
game_score += r
if done:
break
return game_score
def update_weights(self):
self.optimizer.zero_grad()
G_t = 0
for gradient_policy_a_s, r in self.trajectory[::-1]: #cumulative future rewards들의 합 계산을 위해 [::-1]
G_t = 0.99 * G_t + r
loss = -1 * G_t * gradient_policy_a_s # -1 for gradient ascent
loss.backward()
self.optimizer.step()
self.trajectory.clear()
return
class PolicyNetwork(nn.Module):
def __init__(self, input_dim, output_dim, width):
super().__init__()
self.layer1 = torch.nn.Linear(input_dim, width)
self.layer2 = torch.nn.Linear(width, width)
self.layer3 = torch.nn.Linear(width, output_dim)
def forward(self, x):
x = self.layer1(x)
x = torch.nn.functional.relu(x)
x = self.layer2(x)
x = torch.nn.functional.relu(x)
x = self.layer3(x)
x = torch.nn.functional.softmax(x, dim=0)
return x
device = torch.device('cuda:0') if torch.cuda.is_available() else torch.device('cpu')
score_arr = []
env = gym.make("CartPole-v1")
agent = Agent(env.observation_space.shape[0], env.action_space.n, 128)
print(agent)
env.close()
#Self play 및 weight update
episode_nums = 500
for i in range(episode_nums):
game_score = agent.self_play() # play길이 제한 필요시 (max_timestep=값)
score_arr.append(game_score)
agent.update_weights()
if i%50==0 : print('episode', i)
torch.save(agent.state_dict(), 'weights.pt')
agent.env.close()
#Episode별 얻은 score
plt.plot(score_arr, label ='score')
plt.legend(loc='upper left')
#학습된 모델로 게임 play한 영상
agent.load_state_dict(torch.load("weights.pt"))
env = gnwrapper.LoopAnimation(gym.make('CartPole-v1'))
state = env.reset()
for _ in range(200):
with torch.no_grad():
output = agent.forward(torch.from_numpy(state).float().to(device)) # inference
prob_distribution = Categorical(output) #확률분포 표현
action = prob_distribution.sample() #확률분포로부터 action 선택
env.render()
state, rew, done, _ = env.step(action.item())
if done:
state = env.reset()
env.display()







댓글
댓글 쓰기