개요
Proximal Policy Optimization (PPO) 알고리즘을 PyTorch 코드로 구현해보았으며 Colab에서 코드 실행 및 결과 확인이 가능합니다.
설명
Proximal Policy Optimization 알고리즘은 policy gradient류 알고리즘 학습시 발생할 수 있는 collapse(갑자기 성능이 급락하는 경우)를 방지하기 위해서 objective function에 수정을 가한 알고리즘입니다.
Collapse가 일어나는 이유로 policy를 표현할 수 있는 공간 policy space와 이 policy를 parameterize하는데 사용되는 파라미터의 공간 parameter space가 서로 다르기 때문에 update할 때 또한 간극이 있고, step size α가 이 간극을 정확하게 반영하지 못하기 때문이라고 설명될 수 있습니다.
이를 해결하기 위해 TRPO와 같은 알고리즘이 objective function에 특정한 constraint를 걸어서 과도한 업데이트가 일어나지 않게 하는 접근을 취했는데, PPO는 이러한 아이디어를 유지하고 있으면서 구현이 더 쉽고 효율적인 부분들이 있습니다.
PPO의 objective function은 policy를 업데이트하면서 이전 policy와 업데이트된 policy의 performance의 차이에 기반해서 구성을 합니다. 업데이트 한 후의 성능과 이전의 성능이 최대한 크게 차이가 나게끔 gradient ascent를 하면 되는 것입니다.


위 식의 제일 윗줄은 objective를 계산할 때 업데이트 된 policy로부터 얻은 trajectory로부터 advantage A를 계산합니다. 그런데 업데이트 된 policy를 따라서 업데이트 되기 전의 policy를 업데이트 하겠다는 시간상의 모순이 생기는 문제가 있습니다. 때문에 이전 policy로부터 계산가능한 식으로 근사를 해서 사용을 합니다.
PPO는 위의 식을 clip및 min을 사용해서 performance collapse가 일어나지 않는 한도 내에서 최대한 큰 improvement가 일어날 수 있게 하는 식으로 바꿔 사용합니다.


r은 probability ratio입니다.


대략적인 연산 흐름은 다음과 같습니다.
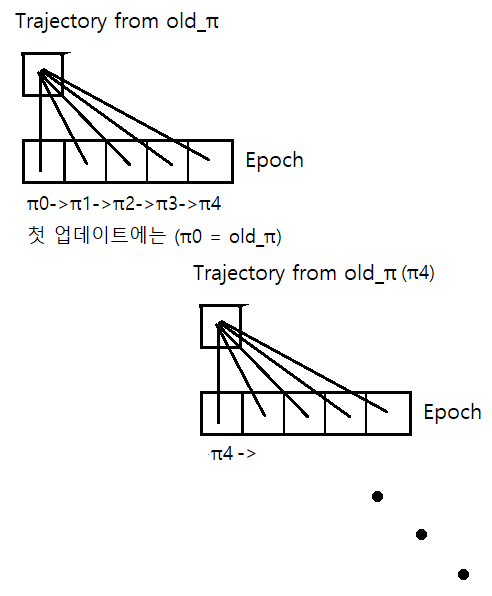
아래는 self_play해서 trajectory모으는 함수 및 weight 업데이트 함수의 코드입니다.
def self_play_old_P(self, max_timestep=1000000):
game_score = 0
state = self.env.reset() # env 시작
for _ in range(max_timestep):
old_state = state
output = self.P(torch.from_numpy(state).float().to(device)) # inference
inferenced_v = self.V(torch.from_numpy(state).float().to(device))
prob_distribution = Categorical(output) #확률분포 표현
action = prob_distribution.sample() #확률분포로부터 action 선택
state, r, done, _ = self.env.step(action.item()) # env 진행
with torch.no_grad():
inferenced_v_from_next_s = self.V(torch.from_numpy(state).float().to(device))
if done==True:
inferenced_v_from_next_s = 0
# old_output,r,v,v_next,old_state, old_action 저장
self.trajectory.append((output, r, inferenced_v, inferenced_v_from_next_s, old_state ,action))
game_score += r
if done:
break
return game_score
def update_weights_PPO(self):
for i in range(5): #epoch
## without minibatch loop now ##
A = 0 #GAE
lam = 0.9
eps = 0.1
self.V_optimizer.zero_grad()
self.P_optimizer.zero_grad()
for old_output, r, v, v_next, old_s, old_a in self.trajectory[::-1]:
with torch.no_grad():
delta = r + 0.99* v_next - v
A += (0.99 * lam) * delta
V_target = A + v
v = self.V(torch.from_numpy(old_s).float().to(device))
V_loss = (V_target.item() - v)**2
V_loss.backward()
output = self.P(torch.from_numpy(old_s).float().to(device))
upper = output.gather(0,old_a)
lower = old_output.gather(0, old_a)
probability_ratio = upper / lower.item()
L_clip = torch.min(
probability_ratio * A.item(),
torch.clip(probability_ratio, 1-eps, 1+eps) * A.item()
)
P_loss = -1 * L_clip
P_loss.backward()
self.V_optimizer.step()
self.P_optimizer.step()
self.trajectory.clear()
return
Gradient계산될 필요가 없는 advantage function 계산 부분은 with torch.no_grad():를 통해 처리하였습니다. 계산그래프상 PolicyNetwork랑 ValueNetwork의 충돌을 막기 위해서 .item() 이나 .detach()를 사용.
매 epoch마다 업데이트된 새 네트워크들로부터 inference를 진행해서 loss계산에 사용해야 합니다.
아래는 학습시 측정한 게임 스코어 그래프입니다(CartPole-v1). PPO의 경우 그래프의 episode축 길이가 300입니다. 다른 알고리즘 대비 성능 증가가 가파른 것을 볼 수 있습니다.

Full code
import gym
import torch
import torch.nn as nn
from torch.distributions import Categorical
import matplotlib.pyplot as plt
!pip install gym[classic_control]
!pip install gym[box2d] #for lunarlander
!apt update
!apt install xvfb
!pip install pyvirtualdisplay
!pip install gym-notebook-wrapper
import gnwrapper
!nvidia-smi
print(torch.cuda.is_available())
class Agent(nn.Module):
def __init__(self, input_dim, output_dim, width):
super().__init__()
self.P = PolicyNetwork(input_dim, output_dim, width)
self.P.to(device)
self.P.train()
self.P_optimizer = torch.optim.Adam(self.P.parameters(), lr=0.0003)
self.V = ValueNetwork(input_dim, output_dim, width)
self.V.to(device)
self.V.train()
self.V_optimizer = torch.optim.Adam(self.V.parameters(), lr=0.0003)
self.trajectory = []
self.env = gym.make(game_name)
def self_play_old_P(self, max_timestep=1000000):
game_score = 0
state = self.env.reset() # env 시작
for _ in range(max_timestep):
old_state = state
output = self.P(torch.from_numpy(state).float().to(device)) # inference
inferenced_v = self.V(torch.from_numpy(state).float().to(device))
prob_distribution = Categorical(output) #확률분포 표현
action = prob_distribution.sample() #확률분포로부터 action 선택
state, r, done, _ = self.env.step(action.item()) # env 진행
with torch.no_grad():
inferenced_v_from_next_s = self.V(torch.from_numpy(state).float().to(device))
if done==True:
inferenced_v_from_next_s = 0
# old_output,r,v,v_next,old_state, old_action 저장
self.trajectory.append((output, r, inferenced_v, inferenced_v_from_next_s, old_state ,action))
game_score += r
if done:
break
return game_score
def update_weights_PPO(self):
for i in range(5): #epoch
## without minibatch loop now ##
A = 0 #GAE
lam = 0.9
eps = 0.1
self.V_optimizer.zero_grad()
self.P_optimizer.zero_grad()
for old_output, r, v, v_next, old_s, old_a in self.trajectory[::-1]:
with torch.no_grad():
delta = r + 0.99* v_next - v
A += (0.99 * lam) * delta
V_target = A + v
v = self.V(torch.from_numpy(old_s).float().to(device))
V_loss = (V_target.item() - v)**2
V_loss.backward()
output = self.P(torch.from_numpy(old_s).float().to(device))
upper = output.gather(0,old_a)
lower = old_output.gather(0, old_a)
probability_ratio = upper / lower.item()
L_clip = torch.min(
probability_ratio * A.item(),
torch.clip(probability_ratio, 1-eps, 1+eps) * A.item()
)
P_loss = -1 * L_clip
P_loss.backward()
self.V_optimizer.step()
self.P_optimizer.step()
self.trajectory.clear()
return
class PolicyNetwork(nn.Module):
def __init__(self, input_dim, output_dim, width):
super().__init__()
self.layer1 = torch.nn.Linear(input_dim, width)
self.layer2 = torch.nn.Linear(width, width)
self.layer3 = torch.nn.Linear(width, output_dim)
def forward(self, x):
x = self.layer1(x)
x = torch.nn.functional.relu(x)
x = self.layer2(x)
x = torch.nn.functional.relu(x)
x = self.layer3(x)
x = torch.nn.functional.softmax(x, dim=0)
return x
class ValueNetwork(nn.Module):
def __init__(self, input_dim, output_dim, width):
super().__init__()
self.layer1 = torch.nn.Linear(input_dim, width)
self.layer2 = torch.nn.Linear(width, width)
self.layer3 = torch.nn.Linear(width, 1)
def forward(self, x):
x = self.layer1(x)
x = torch.nn.functional.relu(x)
x = self.layer2(x)
x = torch.nn.functional.relu(x)
x = self.layer3(x)
return x
device = torch.device('cuda:0') if torch.cuda.is_available() else torch.device('cpu')
score_arr = []
game_name = 'CartPole-v1' #'LunarLander-v2'
env = gym.make(game_name)
agent = Agent(env.observation_space.shape[0], env.action_space.n, 128)
print(agent)
env.close()
#Self play 및 weight update
episode_nums = 300 #LunarLander-v2는 더 길게
for i in range(episode_nums):
game_score = agent.self_play_old_P()
agent.update_weights_PPO()
score_arr.append(game_score)
if i%50==0 : print('episode', i)
torch.save(agent.state_dict(), 'weights.pt')
agent.env.close()
#Episode별 얻은 score
plt.plot(score_arr, label ='score')
plt.legend(loc='upper left')
#학습된 모델로 게임 play한 영상
agent.load_state_dict(torch.load("weights.pt"))
env = gnwrapper.LoopAnimation(gym.make(game_name))
state = env.reset()
for _ in range(200):
with torch.no_grad():
output = agent.P(torch.from_numpy(state).float().to(device)) # inference
prob_distribution = Categorical(output) #확률분포 표현
action = prob_distribution.sample() #확률분포로부터 action 선택
env.render()
state, rew, done, _ = env.step(action.item())
if done:
state = env.reset()
env.display()







댓글
댓글 쓰기