참고한 책 : Reinforcement Learning: An Introduction, 2nd edition (Richard S. Sutton, Andrew G. Barto)
개요
책의 챕터 4는 Dynamic Programming, 챕터 5는 Monte Carlo Methods, 챕터 6은 Temporal-Difference Learning이다. 위 챕터들에서는 MDP로 모델링되는 강화학습 문제를 풀어내는 다양한 방법들을 소개하고 있다. 각 방법들은 사용가능한 상황들, 접근 방법 등이 서로 다르다. 서로 세부적인 부분이 다름에도 prediction problem과 control problem의 관점에서 서술되며 또한 policy evaluation 알고리즘과 policy improvement 알고리즘들도 서술되어 있다.
먼저 generalized policy iteration(GPI)의 관점에서 바라본다. 각 방법들의 공통적인 목적은 최적의 policy를 구해내는 것이다. Generalized policy iteration(GPI)는 policy evaluation이후 더 나은 policy improvement가 가능하고 improvement 이후에는 더 나은 evaluation이 가능한, 이러한 선순환 구조에 기반해서 시작할 때는 불완전했던 policy가 최적인 policy로 수렴해 갈 수 있다는 아이디어이다.

p70, sutton and barto
Evaluation과정에서 policy로부터 value function을 구해내고, 이 value function에 기반해서 생각해보면 그때 제일 좋은 action이 뭔지를 알 수 있으니 그것을 policy에 반영하는 improvement 과정을 반복한다. Evaluation과 improvement를 그림처럼 한번씩 번갈아가는 경우도 있고 한쪽만 먼저 가고 나중에 한번에 반대쪽을 계산하는 경우도 있다. 어찌됐든 최종적으로 optimal한 value function이나 policy로 수렴할 수 있으면 된다.
Prediction problem과 control problem의 관점에서 보면, Prediction problem은 어느 고정된 policy로부터 value function을 구하는 문제이고 control problem은 optimal value function 및 optimal policy를 구하는 문제이다.

Prediction problem은 policy evaluation 알고리즘으로 풀 수 있는 부분이고, control problem은 policy evaluation 및 policy improvement의 협력으로 풀 수 있는 부분이다.
챕터 4 Dynamic Programming은 MDP의 환경에 대한 정보가 완벽한 경우에 사용이 가능하다. DP에서의 계산은 행동을 직접 취해서 결과를 얻지 않고 model로부터 얻는 정보로만 계산한다. Evaluation과정은 bellman equation에 기반하는데 bellman equation처럼 끝까지 전부 한번에 계산하지 않고 한 스텝씩 업데이트 해가며 value function을 천천히 근사해나가는 형태이다.

p61, sutton and barto, DP prediction
Control 문제의 경우 GPI와 같은 형태로 iteration하면서 optimal policy를 근사한다.

p65, sutton and barto, DP control
챕터 5 Monte Carlo Methods는 환경에 대한 정보가 전혀 없이도 쓸 수 있다. 대신 직접 행동을 취해서 직접 보상을 받으면서 정보를 모으고 이에 기반해서 계산을 진행한다. Policy를 따라서 끝까지 들어가보면서 샘플링하는 형태이다. Prediction은 샘플해서 얻은 리턴들의 평균을 사용해 value function을 업데이트한다. MC control 또한 GPI와 같은 형태로 optimal policy를 근사한다.

p76, sutton and barto, MC prediction

p81, sutton and barto, MC control
챕터 6 Temporal-Difference Learning은 위의 DP와 MC를 반반 섞은듯한 형태로 model로부터 얻는 정보와 sample한 정보 모두를 업데이트에 사용한다. 환경에 대한 정보가 없는 상태에서 쓸 수 있고 계산 비용, 속도 측면에서도 장점이 있다. 책의 저자는 이 TD-learning이 강화학습에서 가장 중심이 되는 아이디어라고 이야기한다.
아래 TD(0) prediction 알고리즘은 1-step 떨어진 state s'로 이동하면서 샘플링한 reward와 기존 value function으로부터 알 수 있는 s'의 가치를 더한 것과, 기존 s의 가치의 차이를 업데이트에 반영한다. Step이 n개 떨어진 경우에도 식을 구성할 수 있다.

p98, sutton and barto, TD prediction(TD(0))
이러한 TD의 개념에 기반해서 Sarsa, Q-learning, eligibility traces 등 여러 개념들이 구성된다. 그 중 Sarsa는 TD control 문제 중 하나로 TD의 개념에 기반해 action-value 함수 Q를 업데이트하는 과정을 포함한다. 어떤 state로부터 시작해서 Q로부터 얻어질 수 있는 policy를 따라 action 선택을 하고 이에 따라 다음 s'와 reward를 관측한다. 그리고 s'로부터 다시 a'를 선택하고 이에 따라 TD update식을 구성해 Q를 업데이트한다. 그리고 s', a'로부터 다시 동일한 동작을 반복한다. 이러한 모습이 마치 (sa)-(r)-(sa)의 형태이기 때문이 이름도 sarsa로 지어진 듯 하다.

p106, sutton and barto, TD control(Sarsa)
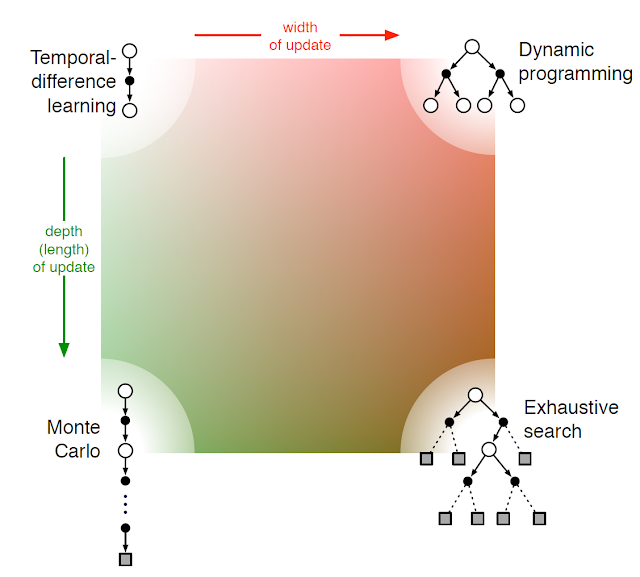
아래 그림은 DP, MC, TD의 계산에 있어서 width 및 depth 관점에서 직관적으로 요약한 그림이다.







댓글
댓글 쓰기