
알파고 Zero가 성능이 더 강해졌다는 것도 물론 대단하지만, 그보다 더 주목할 점이 있습니다. 알파고 Zero는 바둑 기보를 학습하지 않고 강화학습을 진행하였습니다.
바둑 기보 데이터
바둑 기보에는 수십년 동안의 훈련해온 프로선수들의 직관이 풍부하게 담겨 있습니다. 이세돌 선수와 대결했던 알파고를 만들 때, 기보를 학습하는 접근 방법이 사용되었습니다. 이런 방법은 알파고 Lee(이세돌 선수 버전)이 좋은 성능을 낼 수 있게 해주는 바탕이 되어주었습니다.
하지만, 데이터를 모으는 것은 힘든 일입니다. 수십년 동안 수많은 바둑기사들이 대결해온 기보는 10만개 이상 존재합니다. 이렇게 수많은 자료들을 컴퓨터에 직접 입력하고 잘 정리해야 했습니다.
또한 바둑처럼 데이터가 많이 존재하는 경우가 아니라면, 직접 전문가들을 모아 데이터를 만들어야 합니다. 전문가가 많지 않은 분야라면 데이터 구축은 더욱 어려울 것입니다.
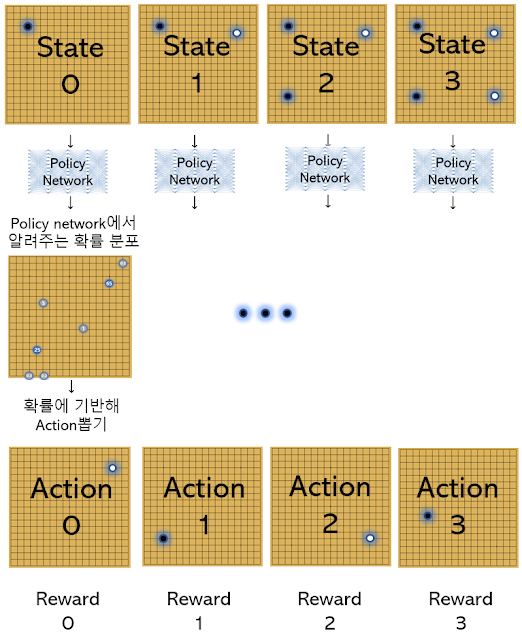 (policy network가 알려주는 확률 분포에 기반해 action을 선택하며 자가대전을 진행)
(policy network가 알려주는 확률 분포에 기반해 action을 선택하며 자가대전을 진행)

 강화학습 시작 후 몇시간 동안은 기보 버전이 훨씬 강력합니다. 처음부터 아마추어의 실력으로 시작하며 빠르게 Elo 레이팅 3000에 도달합니다.
강화학습 시작 후 몇시간 동안은 기보 버전이 훨씬 강력합니다. 처음부터 아마추어의 실력으로 시작하며 빠르게 Elo 레이팅 3000에 도달합니다.
그리고 20시간 이후 기보 버전은 알파고 Lee의 근처에서 더 이상 올라가지 못합니다. 하지만 알파고 Zero는 5000에 가까운 레이팅을 향해 꾸준히 성장합니다.
힘들게 수많은 기록을 모으고, 전문가의 도움을 통해 열심히 데이터를 구축했다고 하더라도 데이터가 100% 좋은 데이터라고 할 수 없습니다. 그 데이터들은 사람으로부터 나온 것이고, 사람 또한 100% 옳을 수가 없기 때문입니다.
그렇기에 데이터를 기반으로 인공지능을 만들면 인공지능 또한 데이터의 한계에 영향을 받게 되고 그에 따른 성능 한계가 존재할 수 있습니다.
알파고 Zero는 기보 데이터 학습 없이 강화학습이 가능한 구조를 갖추게 되면서 데이터의 한계를 넘어서는 높은 성능에 도달할 수 있었습니다. 이는 자가대전 방식의 변화와 강화학습 알고리즘의 변화에 있습니다.
달라진 자가대전 방식
알파고 Lee에서는 자가대전을 진행할 때 수를 두는 판단은 정책 네트워크(policy network)가 담당합니다.
하지만 알파고 Zero는 정책 네트워크가 알려주는 대로 두는 게 아니라, 실제 경기를 할 때처럼 정책 네트워크, 가치 네트워크, MCTS를 사용해 탐색을 진행한 후 얻어낸 확률 분포에 기반해 자가대전을 진행합니다.
Lee는 떠오르는 대로 수를 두는 것에 가깝다면, Zero는 떠오르는 수를 기반으로 조금 더 생각해본 뒤 수를 두는 것에 가깝습니다.
변경된 강화학습 알고리즘
알파고 Lee에서는 policy network를 강화시킬때 REINFORCE알고리즘에 기반했지만, 알파고 Zero는 policy network가 MCTS로 얻어낸 더 나은 확률 분포를 따라하게끔 하는 방법을 통해 policy network를 강화합니다.
 알고리즘을 반복할수록 policy network는 갈수록 더 나은 확률 분포를 나타내게 되며, 성능 또한 높아지게 됩니다.
알고리즘을 반복할수록 policy network는 갈수록 더 나은 확률 분포를 나타내게 되며, 성능 또한 높아지게 됩니다.
바뀐 알고리즘의 성과
이렇게 바뀐 알고리즘은 기보 데이터로 policy network를 훈련시키지 않은 상태에서 강화학습을 시작해도 안정적으로 성능이 향상되는 장점이 있습니다. 게다가 기보 데이터의 한계를 넘어 더 높은 성능에 도달할 수 있습니다.연구팀은 기보를 학습한 후 강화학습을 하는 기보 버전(Supervised learning)과, 배우지 않고 강화학습을 하는 Zero(Reinforcement learning)를 비교해 보았습니다.
Zero의 경우 돌을 집어던져서 두는 것과 같은 수준의 레이팅인 -3000에서부터 시작합니다. 하지만 계속해서 자가대전을 통해 강화하여 20시간 후에는 기보 버전을 넘어섭니다.
그리고 20시간 이후 기보 버전은 알파고 Lee의 근처에서 더 이상 올라가지 못합니다. 하지만 알파고 Zero는 5000에 가까운 레이팅을 향해 꾸준히 성장합니다.
기보 버전은 데이터가 가진 한계에 영향을 받아 최대 성능이 제한된 것으로 볼 수 있습니다. 반면 데이터 없이 학습한 Zero는 데이터의 한계를 뛰어넘는 높은 성능에 도달할 수 있었습니다.
알파고 Zero는 이제 바둑을 잘 두는 것 뿐 아니라 바둑을 이해하고 학습하는 부분에 있어서도 사람보다 우위에 서게 된 것 같습니다. 어떤 데이터도 학습하지 않고 프로 선수들이 수십년 동안 경기와 복기를 통해 찾아낸 전략들보다 더 나은 전략을 학습했습니다.
글을 마치며
이렇게 기보 데이터 없이도 강력한 바둑 인공지능 프로그램 개발이 가능한 강화학습 알고리즘이 만들어지게 되었습니다. 하지만 아직 바둑에만 적용 가능한 알고리즘이라는 한계가 있습니다.







댓글
댓글 쓰기